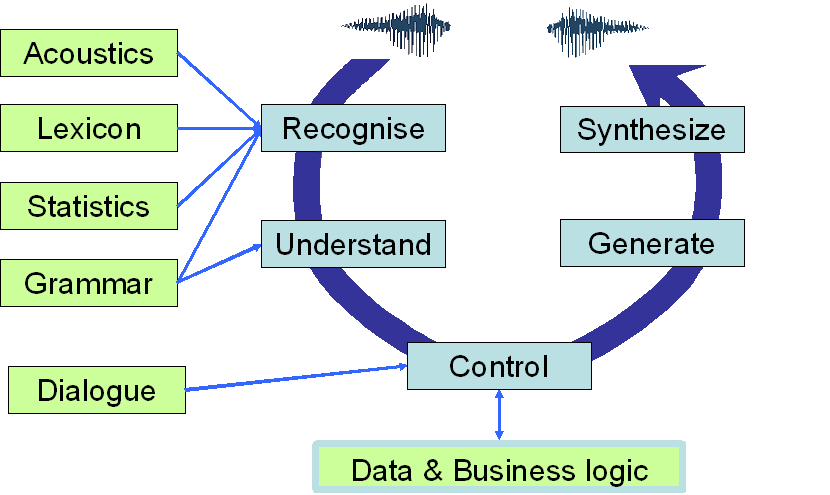
Speech Interaction Theory
Spoken language is very different from written language [Baggia et al. 1994, Waibel 1996]. One of the differences is that people typically do not follow rigid syntactic and morphological constraints in their utterances (cf. speech characteristics). This lack of written-language formality in spontaneous spoken language makes linguistic analysis-by-machine both more difficult than, and different from, analysis of written language. However, Waibel [1996] reports that although cross-talk data have lower recognition accuracy (70%) than push-to-talk data (71% recognition accuracy), the transaction success in terms of speech-to-speech translation performance is much better for cross-talk dialogues (73%) than for push-to-talk dialogues (52%). One explanation is that although more different from written language than push-to-talk speech, cross-talk produces shorter turns that are easier to translate. The corresponding, added difficulties involved in the generation of spoken language are less pronounced, if only because human interlocutors are much more capable of decoding the machine’s spoken messages.
The language layer includes two types of elements: user (input) utterances and system (output) utterances. The term ‘utterance’ is vague - some would say, fruitfully so - such as in the following definition: an utterance is a coherent, linguistically meaningful message that a person speaks during conversation [Nofsinger 1991, Traum and Heeman 1996]. We shall be using the terms ‘turn’, ‘utterance’ and ‘utterance unit’ as follows: a turn is what is being said by an interlocutor from when this interlocutor starts speaking and until another interlocutor definitely takes over. A turn may consist of one or more utterance units (or sub-utterances). Capitalising on the vagueness of the term, an utterance is a turn or an utterance unit. Normally, turns are easily recognised by the machine. Yet problems remain with the classification of turns which include talk-over and, perhaps, turns which include very long pauses [Traum and Heeman 1996]. We shall be treating talk-over as consisting of utterance units overlaid onto somebody else’s turn. Utterance units are much more difficult to recognise by machine than are turns, given the non-sentential characteristics of much of spoken language. It remains to be seen, however, whether this is a difficulty to be overcome by future progress in spoken language processing or whether the difficulty will just go away because systems do not need to recognise utterance units anyway.
The elements subsumed by user (input) utterances and system (output) utterances are: input lexicon, input grammar, input semantics, input style, output lexicon, output grammar, output semantics, and output style.
User utterances
The lexicon is a list of words, a vocabulary, annotated with syntactic (including morphological) and semantic features. The fact that vocabularies of current interactive speech systems are still limited, implies that some application domains cannot be addressed because the required vocabulary is too large. For those applications which may be addressed as far as their expected vocabulary size is concerned, the problem is to identify the vocabulary, and hence the lexicon, that the application needs.
Vocabulary identification is part of the larger enterprise of determining the sub-language for the application, including vocabulary as well as grammar. For the moment, sub-language identification has to be done empirically through simulation experiments, domain studies, human-human spoken interaction in the domain and/or field studies of user interaction with a system prototype.
Convergence is an important measure of success in sub-language vocabulary development. It means that iterated user-system interactions produce less and less new words that have to be included in the system’s lexicon, thus converging on zero which is the situation in which the system has the vocabulary it needs for the application. Strictly speaking, convergence is a pragmatic notion. One can always find additional, more or less out-of-the-ordinary words and phrases which may be used in accomplishing the task and which the system does not have in its lexicon. For instance, although the Roman Catholic Saints calendar references were once known in Denmark, still survive in fragments, and can be used in uniquely identifying travel dates, these references have not been included in the lexicon for the Danish Dialogue System.
Grammars describe how words may be combined into phrases and sentences. The input grammar for the application is specified empirically as part of the sub-language identification process. An important goal in input grammar specification is to include all intuitively natural grammatical constructs, possibly up to a certain level of complexity, in the system’s input grammar. Users will have little patience with a system which does not accept perfectly ordinary and grammatically simple ways of saying things.
User utterances usually consist of one or several lexical strings or graphs received from the recogniser. In some systems, linguistic analysis of user utterances is done by parsers which use grammars derived from written language processing. This is the case in the Danish Dialogue System (Figure 1). The excessive formality of written prose as compared to spoken language (cf. above) means that the system must apply "robust parsing" or "error" recovery procedures when the ordinary parsing fails [Music and Offersgaard 1994, Povlsen 1994]. A promising approach to robust parsing is to focus the analysis on sub-sentences and phrases [Aust et al. 1995].
| Input: Word String |
"Den elvte" (the eleventh) |
|---|---|
| Lexicon |
den_1 = { lex=den, dalu=den, cat=det, scat=no,
defs=def, gend=comm, nb=sing }.
elvte_1 = { lex=elvte, dalu=elvte, cat=ord,
scat=date, mth=yes, post_comb=no, int=11}.
|
| APSG: Augmented Phrase Structure Grammar |
date_p_1a =
{cat=date_p}
[{cat=det, scat=no, nb=sing, gend=comm},
{cat=ord_p, scat=date}
].
|
| Semantic Mapping Rule |
date_p_map2a = { sem={day={ones={number=C}}}
{cat=date_p}}
[ {cat=det},
{cat=ord_p}
[ {cat=ord, scat=date, int=C}
]
].
|
| Output: Semantic Object |
day = {ones={number=11}}}
|
Semantics are abstract representations of the meanings of words, phrases and sentences. We shall not go into issues such as the selection of semantic formalisms for interactive speech systems or the advantages or disadvantages of carrying out syntactic and semantic analysis sequentially or in parallel. In the Danish Dialogue System, syntactic and semantic analysis is done in parallel. Lexical entries are defined as feature bundles including lexical value, category (determiner, ordinal), semantic category (none, date), gender (common) and selectional features (‘elvte’ can be a month), cf. Figure 1. The grammar has several rules describing the construction of dates. Figure 1 shows the rule for forming a date from a determiner and an ordinal. The semantic mapping rules extract semantic values from syntactic sub-trees. The figure shows a rule for the extraction of a date from a sub-tree created from the Augmented Phrase Structure Grammar (APSG) rule example.
In general, style may be analysed in terms of the vocabulary used, which may be formal or informal, slang etc., sentence length, use of adjectives, figures of speech, synonyms, analogies, ellipses, references etc. [Jones and Carigliano 1993]. Style is generally described in terms such as terseness and politeness. In interactive speech systems, user input style may be considered an important dependent variable which must be influenced through instruction and example. The aim is to avoid that users address the system in styles that involve lengthy, verbose or convoluted language, such as when users are excessively polite. A system introduction to that effect would appear useful in many cases, cf. the example. Influencing user input style by example is done through the system’s output (see below).
System utterances
The design of system utterances is important to the user’s perception and understanding of, and successful interaction with, the system as well as to how the user will address the system. It is somewhat difficult to distinguish between the effects of output lexicon, output grammar, output semantics and output style. It seems to be a well-established fact that the system’s style of speaking influences the way the user addresses the system. If the system is overly polite, users will tend to address the system in a verbose fashion that does not sit well with the need for brief and to-the-point user utterances that can be handled by current speech and language processing [Zoltan-Ford 1991]. Style is a function of, among other things, grammar and lexicon (cf. above). It seems plausible, therefore, that output grammar and output lexicon do influence the grammar and lexicon to be found in the user’s input. It follows (i) that the output lexicon should not include words which the user may model but which are not in the input lexicon; and (ii) that output grammars should not inspire the user to use grammatical constructs which the system cannot understand.
The generation of system utterances is determined by elements in the control and context layers. For instance, the interaction level limits the form of user response expected and should be made clear in the system’s utterances; the output vocabulary and language (formal or informal, etc.) is determined by the expected user group; the attentional state determines the narrowness of system questions (see below); and the interaction level, references, segment structure and speech acts may dynamically affect the kind and form of feedback from the system (see below).
System questions differ on a narrow-to-open scale, influenced by the attentional state. A narrow or focused question concerns a single topic, such as in "Where does the journey start", whereas an open or unfocused question invites the user to address a range of different topics, as in "How can I help you?". The current version of the Danish Dialogue System ends the reservation task by asking the question on the left in Figure 2. However, although the intention was to elicit a yes/no answer from the user, many users would take the opportunity of the system’s open request to raise any issue lingering on their minds from the preceding interaction. The system cannot handle such input and it is clear that the more specific and narrow question on the right is preferable. It does the job needed without inviting unpredictable user input. In other words, open questions are dangerous and should only be used in interactive speech systems when the task is constrained enough for the system to manage whatever the co-operative user may say.
| S: Do you want more? | S: Would you like to make another reservation? |
It is useful to distinguish between explicit and implicit feedback (also called direct and indirect confirmation). In providing explicit feedback the system asks for explicit verification of the recognised input, whereas in providing implicit feedback the system merely includes the feedback information in its next turn and immediately carries on with the task. If the user accepts the feedback, no explicit response from the user is required. The example in Figure 3 is adapted from Philips’s train timetable inquiry system [Aust et al. 1995]. The drawbacks of explicit feedback are an additional risk of system misunderstanding (the requested user answer may be misunderstood), and that explicit feedback demands additional turn-taking. By comparison, however, the implicit feedback (right) makes it easier for users to ignore the system’s feedback, a problem also seen in the Danish Dialogue System. Niimi and Kobayashi [1995] show mathematically that explicit feedback may increase the probability that information in the user utterance is correctly conveyed, and that implicit feedback may reduce the average number of turns exchanged.
| S: So you would like to go from Hamburg to Berlin? | S: When would you like to go from Hamburg to Berlin? |
A second distinction is between immediate feedback and summarising feedback. The difference is shown in the examples in Figure 4. On the left, the system provides immediate feedback. On the right, the route information provided by the user is not confirmed until the end of the route sub-task (S3a). The two forms of feedback do not exclude each other (cf. S13b in the example).
|
|
System co-operativity throughout the interaction is a function of its output semantics and, to a lesser extent, output style.
The above is adapted for web from [Bernsen et al. 1998b].