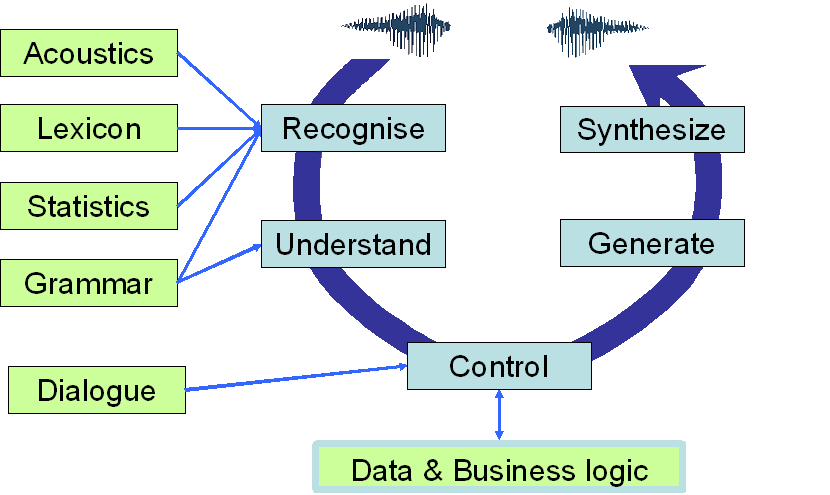
Speech Interaction Theory
Though there is not a universally accepted complete theory of speech interaction, there is a number of concepts which it is useful to know and to put into relation to each other when building spoken dialogue systems. The theory outlined here builds on [Bernsen et. al. 1998b, pp29-60], see also [Möller 2004 pp43-47]. The figure only contains a selection of all the concepts.
| (Click labels to read more) (show all) |
System performance
A function of the other layers, expresses how the application behaves towards the user.
Cooperativity
Assuming that the system is task-oriented, the behaviour should be cooperative.
Initiative
Traditionally, the system has the initiative in order to be in control and constrain the focus.
However, the tendency goes towards more mixed-initiative systems. In smaller systems the user may say anything within the task domain at all times.
Influencing user behaviour
Via style and priming, the system may influence how the user behaves.
|
Speech input
The input is spoken language. In concrete applications other modalities, e.g. touch-tone, may be added.
Acoustic models
Describe the building blocks of speech. Can be any kind piece of speech, but is today often a set of phoneme models which are then put together in larger chunks via Hidden Markov Models.
Grammar
When accepting continuous speech, words are pieced together via a simple syntactic model such as bigram or finite state grammar. Typical spoken language phenomena like repetitions and ehm's should be taken care of, too.
Prosody
The voice itself conveys a number of phenomena related to the structure and meaning of the input, such as intonation (e.g. a questioning voice), glottal stops, stress, and awareness markers. Though not strictly prosodic, voice can also have qualities like happiness, anger, tiredness, having a cold, etc. that are not linguistic, but convey meaning in a conversation.
Speech output
The computer generates acoustic speech from its internal structural representation of output.
Coded speech
Coded speech or canned phrases is pre-recorded words and phrases which are concatenated and replayed. It dominant in spoken dialogue systems because it provides a natural voice. However, it is difficult and costly to maintain the system.
Parametric speech
Parametric or synthetic speech is generated based on a model of human speech. Prosodic features may be included, but are difficult to get right due to the sensitiveness of the human ear. Today, commercial syntheses exist which are quite natural and dynamic.
Prosody
Using coded speech prosodic features can be achieved in systems with limited output structure, but at a high maintenance cost. This also applies to feelings etc. Parametric speech begin to exhibit doable prosodic features, but still don't express feelings etc.
|
User utterances
Spoken language and in particular interactional language is quite different from standard written language. E.g the basic unit is ellipsis rather than sentence, and in human-human conversation utterances are often built by the participants together [Steensig 2001
Lexicon
The lexicon describes what words can be used. It connects to the speech layer via a phonetic transcription in e.g. SAMPA.
Grammar
The grammars analyze words into utterance wide structures.
Semantics
Typically, unification or attribute grammars are used to extract the core concepts with meaning attributes. This may be supplemented with semantic rules using history and domain knowledge.
Style
Individual users or groups of users may speak in specific ways that can be modelled to understand and recognise them better.
System utterances
The design of system utterances is important to the user's perception and understanding of, and successful interaction with, the system as well as to how the user will address the system. The system output is a function of the user input, the current state, the acts that should be expressed and the content values to express, and is formed by e.g. the principles of cooperativity and priming.
Lexicon
In principle the words used by the system should be a subset of those the user can use and be recognised.
Grammar
In today's simple task-oriented systems, output is often generated via straightforward output templates with slots for concrete task domain values. In principle, and certainly needed in advanced systems, more complex generative grammars will be needed.
Semantics
The semantics together with style determine the system's cooperativity.
Style
Should the system be formal, information, terse, talkative, etc.?
|
Attentional state
We use the term attentional state [Grosz and Sidner 1986] to refer to the elements that concern what is going on in the interaction at a certain point in time. The attentional state is inherently dynamic, recording the important objects, properties and relations at any point during interaction
Focus
The focus is the topic which is most likely to be brought up in the next user utterance. For instance, if the system has asked for a departure airport, this topic will be in focus with respect to the next user utterance. If the user instead provides a destination airport this may still be understood if included in the focus set.
Expectations
Expectations may be attributed to the system if not all sub-tasks are in the focus set. Then expectations serve as a basis for constraining the search space by selecting the relevant sub-set of the acoustic models, the lexicon and the grammars to be active during processing of the next user input. If the user chooses to address other sub-tasks than those in the focus set, system understanding will fail unless some focus relaxation strategy has been adopted. The more stereotypical the task structure is, the easier it is to define appropriate expectations provided that the user is co-operative.
Intentional state
Intentional structure [Grosz and Sidner 1986] to subsume the elements that concern tasks and various forms of communication. These elements all concern intentions, or goals and purposes.
Tasks
Intentions can be of many kinds, such as to obtain information, make somebody laugh, or just chat, and are in general not tied to tasks. In today’s interactive speech systems, however, spoken human-computer interaction is performed in order for a user to complete one or more tasks. From this task-oriented, shared-goal viewpoint, intentions coincide with task goals.
Communication types
In task-oriented systems one may distinguish between the communication types domain communication, meta-communication which has a crucial auxiliary role in spoken human-machine interaction which is essential because of the sub-optimal quality of the systems’ recognition, and other forms of communication such as opening and closing of the dialogue.
Interaction level
The interaction level xpresses the constraints on user communication that are in operation at a certain stage during interaction.
Linguistic structure
The linguistic structure subsumes high-level structures in the input and output discourse [Möller 2004]
Speech acts
Speech acts is about what people do with their utterance, and the identification of speech acts constitutes a useful tool for understanding the spoken discourse, even though there is no universally recognised taxonomy of of speech acts.
References
The problem of references (or, strictly speaking, co-references) concerns that many different words or phrases can refer to the same extra-linguistic entity or entities. References are are important to real fluent and natural conversation. However, most spoken dialogue systems parse input only partially, not considering more than rather trivial references.
Discourse segments
Supra-sentential structures in the discourse. They are the linguistic counterparts of task structure and in the conversational theory of Grosz and Sidner [1986], intentions are restricted to those that are directly related to discourse segments.
|
Interaction history
Context is of crucial importance to language understanding and generation and plays a central role in interactive speech systems development. The context provides constraints on lexicon, speech act interpretation, reference resolution, task execution and communication planning, system focus and expectations, the reasoning that the system must be able to perform and the utterances it should generate. Contextual constraints serve to remove ambiguity, facilitate search and inference, and increase the information contents of utterances since the more context, the shorter the messages need to be [Iwanska 1995]. Specification of context is closely related to the specific task and application in question. In a sense, each element is part of the context of each other element.
Linguistic
The linguistic history records the surface language, its semantics and possibly other linguistic aspects such as speech acts and the order in which they occurred. The linguistic history encapsulates the linguistic context and is necessary in advanced systems in which the linguistic analysis is no longer context free. For instance, the capture of surface language is needed in cross-sentential reference resolution.
Topic
The topic history records the order in which sub-tasks have been addressed. The topic history encapsulates the attentional context and is used in guiding system meta-communication.
Task
The task history stores the task-relevant information that has been exchanged during interaction, either all of it or that coming from the user or the system, or some of it, depending on the application. The task history encapsulates the task context. It is used in executing the results of the interaction and is necessary in most interactive speech systems. The task history may be used in providing summarising feedback as in the Danish Dialogue System.
Performance
The performance history updates a model of how well interaction with the user is proceeding. The performance history encapsulates the user performance context and is used to modify the way in which the system addresses the user. Thus the system may be capable of adapting to the user through changing the interaction level.
Domain model
The domain of an interactive speech system determines the aspects of the world about which the system can communicate. The system usually acts as front-end to some application, such as an email system or a database. The domain model captures the concepts relevant to that application.
Data
Data usually are stored in an application database.
Rules
During domain-related interaction the system evaluates each piece of user input by checking the input with the application database and/or already provided information stored in the task history.
User model
Speech systems should be carefully crafted to fit the behaviour of their users. The better the system can take aspects such as user goals, beliefs, skills, preferences and cognition into account, the more co-operative the system can be.
Goals
User goals determine which tasks and sub-tasks the system actually has to execute among those that the system is capable of performing.
Beliefs
What some or all users believe to be true of the system, the domain and relevant states of affairs in the world.
Preferences
Options preferred by all, or some, users, such as to let departure time depend on discount availability (domain related), to perform the interactive task in a certain order, or to have the initiative during interaction (interaction related). The latter preference, like many user preferences, may be regarded as a soft constraint, i.e. a constraint that may be ignored at development time if harder constraints have to be satisfied.
User group
Represent relevant classifications of potential users. The novice-expert distinction could be one such classification.
Cognition
Developers should keep in mind that users have to perform rapid, situation-dependent cognitive processing during interaction and that users’ capabilities of doing so are severely limited.
|