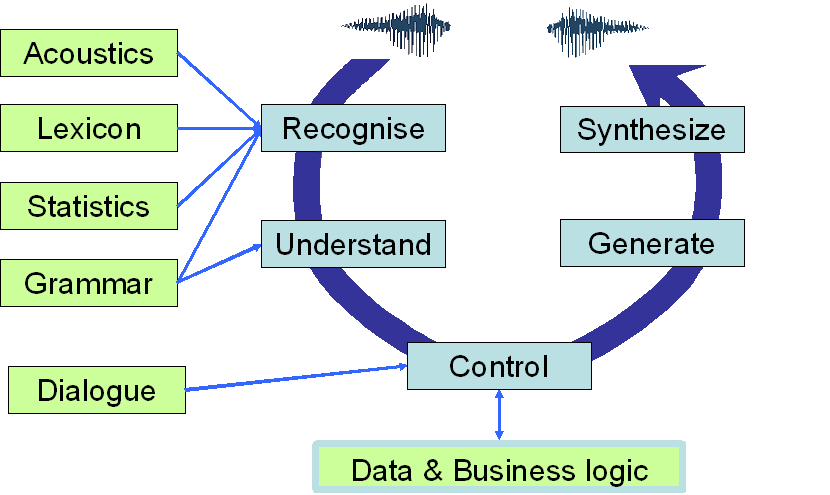
Speech Interaction Theory
Controlling the interaction is a core function in interactive speech systems. Interaction control determines what to expect from the user, how to interpret high-level input structures, consultation of the context elements, what to output to the user, and generally when and how to do what. Being done at run-time, control builds on structures determined at development time. The nature of these control tasks implies that control has to operate on superordinate interaction structures and states. Following [Grosz and Sidner 1986], the interaction model distinguishes three types of superordinate interaction structure and state. The attentional state includes the entities in current interaction focus. The intentional structure addresses the purposes involved in interaction, and the linguistic structure includes characterisation of high-level structures in the input and output discourse.
Attentional state
We use the term attentional state [Grosz and Sidner 1986] to refer to the elements that concern what is going on in the interaction at a certain point in time. The attentional state is inherently dynamic, recording the important objects, properties and relations at any point during interaction. The system represents the attentional state as a focus set. The focus set includes the set of sub-tasks about which the system is currently able to communicate. The focus set may include all sub-tasks as in the Philips timetable information system, or only a sub-set thereof as in the Danish Dialogue System. The latter strategy is used if only a sub-set of the system’s input vocabulary and grammar can be active at any one time.
The focus is the topic which is most likely to be brought up in the next user utterance. For instance, if the system has asked for a departure airport, this topic will be in focus with respect to the next user utterance. If the user instead provides a destination airport this may still be understood if included in the focus set.
Expectations may be attributed to the system if not all sub-tasks are in the focus set. Then expectations serve as a basis for constraining the search space by selecting the relevant sub-set of the acoustic models, the lexicon and the grammars to be active during processing of the next user input. If the user chooses to address other sub-tasks than those in the focus set, system understanding will fail unless some focus relaxation strategy has been adopted. The more stereotypical the task structure is, the easier it is to define appropriate expectations provided that the user is co-operative. In the Danish Dialogue System, information on sub-tasks in system focus is hardwired. This means that expectations are static, i.e. they are fixed at run-time. This approach will not work for mixed initiative dialogue because there the user has the opportunity to change (sub-)task by taking the initiative. When part of the initiative is left to the user, deviations from the default domain task structure may be expected to occur. In such situations, the system should be able to determine the focus set at run-time. Mixed initiative dialogue therefore either requires a dynamically determined focus set or an unlimited focus set.
Intentional structure
We have chosen the term intentional structure [Grosz and Sidner 1986] to subsume the elements that concern tasks and various forms of communication. These elements all concern intentions, or goals and purposes. We distinguish between tasks, communication types, and interaction level. The intentional structure serves to control the transactions of the system.
Intentions can be of many kinds, such as to obtain information, make somebody laugh, or just chat, and are in general not tied to tasks. In today’s interactive speech systems, however, spoken human-computer interaction is performed in order for a user to complete one or more tasks. From this task-oriented, shared-goal viewpoint, intentions coincide with task goals. According to [Grosz and Sidner 1986], an intention I1 is said to dominate another intention I2 if the satisfaction of I2 contributes to and serves to satisfy I1. And intention I2 has precedence to I3 if it is necessary to satisfy I2 before it is meaningful or possible to satisfy I3. Similarly, a task T1 may include a sub-task T2, and T2 may have to precede T3. For example, to make a flight reservation one must determine, among other things, a route (origin and destination) and a time. Reservation thus includes the sub-tasks route and time. Moreover, as it is meaningless to determine the departure time until the route has been determined, route precedes time. Note that relevant intentions need not show up during interaction. For instance, one of the system’s tasks in executing a reservation is to compute the price of the ticket. Although it might be co-operative to do so, a realistic application would not necessarily inform the user of the computed price but might simply store it in the reservation file.
A single interactive speech system may be able to accomplish several different superordinate tasks. These may all belong to a single domain, such as when the system both performs ticket reservation and provides information on a variety of travel conditions that are not directly related to ticket reservation; or the superordinate tasks may belong to unrelated domains such as the provision of telephone access to email, calendar, weather and stock exchange information [Martin et al. 1996].
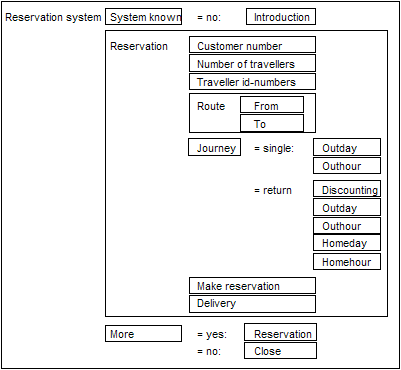
We distinguish between well-structured and ill-structured tasks. Well-structured tasks have a stereotypical structure that prescribes (i) which pieces of information must be exchanged between the interlocutors to complete the task, and often also (ii) a natural order in which to exchange the information. If the stereotype is known, shared and followed by the interlocutors, the likelihood of successful completion of the task is significantly increased. Stereotypical tasks, even when comparatively large and complex, are well-suited for the predominantly system directed or user-directed interaction that is characteristic of today’s interactive speech systems. An example is the ticket reservation task stereotype of the Danish Dialogue System shown in Figure 1. This structure conforms to the most common structure found in corresponding human-human reservation task dialogues recorded in a travel agency [Dybkjær and Dybkjær 1993f]. Another example is MERIT [Stein and Maier 1994] in which strategies captured by dialogue scripts suggest or prescribe certain sequences of dialogue acts. Strategies are global structures that combine speech acts into larger, meaningful sequences. Strategies correspond to task templates and are domain dependent and prescriptive.
Ill-structured or non-stereotypical tasks contain a large number of optional sub-tasks whose nature and order are difficult to predict. An example would be a comprehensive information system on travel conditions. This system would include many different kinds of information at many different levels of abstraction, such as fares, general discount rules, discounts for particular user groups or particular departures, departure times, free seats, rules on dangerous luggage, luggage fees, rules on accompanying persons, pets etc. In specifying the Danish Dialogue System we found that a complex information task of this nature could not be modelled satisfactorily for being accomplished through system directed interaction. The problem was that a user might want a single piece of information which could only be retrieved through a lengthy series of answers to the system’s questions. This difficulty might be overcome through more sophisticated interaction models, such as the use of advanced mixed initiative dialogue combined with the use of larger active vocabularies than we had at our disposal.
Given a task-oriented approach to interaction theory, there is a relatively clear distinction between three types of interaction between user and system. The first is basic, task-oriented interaction or domain communication, which is what the dialogue is all about. We illustrate considerations pertinent to domain communication design through considering questions and feedback.
The second interaction type is meta-communication which has a crucial auxiliary role in spoken human-machine interaction. Meta-communication serves as a means of resolving misunderstandings and lacks in understanding between the participants during task-oriented dialogue. In current interactive speech systems, meta-communication for interaction repair is essential because of the sub-optimal quality of the systems’ recognition and linguistic processing of spontaneous spoken language. Similarly, meta-communication for interaction clarification is likely to be needed in all but the most simple advanced interactive speech systems.
Domain communication depends on the domain and the dialogue model. Models of meta-communication, on the other hand, might to some extent be shared by applications which are different in task and/or domain [Bilange 1991]. It should be remembered, however, that meta-communication is often domain dependent, such as in "Did you say seven o’clock in the morning?".
In addition to domain- and meta-communication, most interactive speech systems need other forms of communication which do not belong to either of these two categories, such as opening and closing of the dialogue and communication about the system. We shall not go into a deeper analysis of these examples.
Finally, the interaction level expresses the constraints on user communication that are in operation at a certain stage during interaction. At least the five levels listed in Figure 2 may be distinguished. The interaction level may require hard constraints to be imposed on the user’s vocabulary, grammar and style. In the extreme, the system may ask the user to spell the input (Level 1). At the other extreme, no constraints on user input exist beyond those of general user co-operativity (Level 5).
| Level | Expected input | |
|---|---|---|
| 1 | Spell. How do you spell the name? |
The answer is spelled. ‘B’ ‘e’ ‘r’ ‘n’ ‘s’ ‘e’ ‘n’ |
| 2 | Yes/no. Do you want a return ticket? |
Yes or no. Yes. |
| 3 | Multiple choice. Do you want a one-way or return ticket? |
List of acceptable values. A return ticket, please. |
| 4 | General but focused. Which day does the journey start? |
Any answer within current focus. Monday next week. |
| 5 | General and unfocused. How may I help you? |
Any answer. Can I take a cat with me on the flight? |
The notion of interaction level has been employed in graceful degradation. Graceful degradation is a strategy for meta-communication according to which the system, in a stepwise fashion, adds constraints on user input to facilitate comprehension. In the Sundial project [Heisterkamp 1993] graceful degradation was deployed in this way in case of system understanding failure. When interaction levels are used for this purpose, the level of expected input must be made clear to the user. There is not a one-to-one relation between system phrases and interaction level. For instance, the system’s "Do you want more?" which literally is at the yes/no level is pragmatically being interpreted as belonging at the general and unfocused level.
Linguistic structure
The linguistic structure of the interaction includes the elements: speech acts, references and discourse segments.
The speech act is a basic unit of conversational theory [Searle 1969]. All speech acts have propositional content, that is, the state of affairs addressed by a particular speech act, such as "departure at 8 o’clock". Instances of different types of speech act may have the same propositional content. What distinguishes them, and hence what distinguishes different types of speech act, is what the speakers do with their speech. The departure at 8 o’clock, for instance, may be questioned, promised, ordered etc. In the request in S9a in Figure 3 "On which date does the journey start?", the system tries to make the user respond with an inform statement whose propositional content is a date, which follows in U9a. Speech acts are often called dialogue acts [Bunt 1994, Stein and Maier 1994] or moves [Carletta et al. 1996a].
| Topic | Number | Act | Utterance |
|---|---|---|---|
| date | S9a | [request] | [..3] On which date does the journey start? |
| U9a | [inform] | [.] [Ehm] A Friday. | |
| S10a | [confirm] | [..11] Friday the 13 of January. | |
| S10b | [request] | At which time? | |
| meta | U10a | [request] | [..2] Change. |
| date | S11a | [inform] | [..3] The journey starts on Friday the 13 of January. |
| S11b | [request] | Is this correct? | |
| U11a | [inform] | No. |
What types of speech acts are there? Searle [1969, 1979] identified the five generic speech act categories shown in Figure 4. Useful and even fundamental as these five types may be, they are not likely to be sufficient for interactive speech systems development purposes. Although much work has been going on lately on this issue [Dybkjær and Heid 1996], there still is no universally recognised taxonomy of speech acts available at a more detailed level. The speech acts types which have been added during annotation in Figure 3 thus cannot claim any particular status, neither theoretically nor in terms of standardisation. Still, speech act identification not only constitutes a useful tool for increasing current understanding of spoken discourse, there is also good reason to believe that speech act identification by machine will be necessary in future advanced interactive speech applications. Clearly, it can make a huge difference to the system’s understanding of, and action upon, user input whether the user expressed a commitment to book a certain ticket or merely asked a question.
A particular problem is that speech acts can be indirect as well as direct. In a direct speech act, the surface language expresses the intended speech act. An indirect speech act is one in which the surface language used does not disclose the "real" act intended by the user. For instance, if someone asks if you have a match, it is likely that the question is not being asked merely in order to be able to record the fact. Rather than being a request for information, this act is a request for the act of providing fire for some purpose, such as lighting a candle. Indirect speech acts remain difficult to identify by machine. Several interactive speech research systems projects have been, or are, wrestling with this problem, such as Esprit PLUS [Grau et al. 1994] and Verbmobil [Jekat et al. 1995].
| Assertives | Commit the speaker to something being the case. E.g. "There is a departure at 8 o’clock." |
|---|---|
| Directives | Represent attempts by the speaker to get the hearer to do something. E.g. "Answer the questions briefly and one at a time." |
| Commissives | Commit the speaker to some future course of action. E.g. "I would like to reserve a ticket for Copenhagen." |
| Expressives | Express the psychological state with respect to a state of affairs specified in the propositional contents. E.g. "Sorry, ..." |
| Declaratives | Bring about some alteration in the status or condition of the referred object solely in virtue of the fact that the declaration has been successfully performed. E.g. "You have now booked one ticket for ..." |
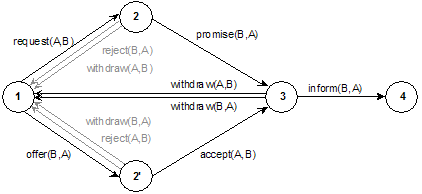
A typical use of speech acts in interactive speech systems is to arrange them in a network to control the local exchange structure of the interaction. The computational roles model (COR) defines the local dialogue structure by sequencing it into dialogue acts (Figure 5). The COR model is symmetric with respect to user and system and defines a hierarchical structure in which atomic dialogue acts are combined into moves. The COR model has been used in several systems, such as MERIT [Stein and Maier 1994] and SPEAK! [Grote et al. 1997].
The handling of references (or, strictly speaking, co-references) is a classical problem in linguistics. The problem is that many different words or phrases can refer to the same extra-linguistic entity or entities. Basically, language is not about itself, although it can be, but about something extra-linguistic. This means that expressions referring to extra-linguistic entities abound in written text and spoken discourse. Often, two or more expressions refer to the same extra-linguistic entity. Normally, the first occurrence of an expression will make its extra-linguistic reference quite clear. This is not always true but may perhaps be taken for granted in practical, task-oriented written text and spoken discourse. However, given that the first expression has made clear its extra-linguistic reference, language offers many ways of economising with the following, co-referring expressions, i.e. the expressions which have the same extra-linguistic reference as the first one. For instance, the system might say "Should the tickets be sent or will they be picked up at the airport?", to which the user might answer, using a pronoun instead of the original noun phrase (the tickets): "They should be sent". Humans are very good at resolving co-references, such as the one in the systems utterance "... the tickets (i.e. the flight tickets around which the entire dialogue has been evolving)...". So the system’s human interlocutor is not the problem. However, current systems are far from experts in resolving co-references such as the one in the user’s answer "They (i.e. the tickets) ...". So what do they do if they are "realistic" systems like the Danish Dialogue System and not specifically built to explore co-reference resolution algorithms?
Possibly the simplest answer to the question of the state-of-the-art in co-reference handling in current realistic interactive speech systems, is that co-reference is not being handled at all but that the problem of co-reference constitutes one of the many reasons why many systems perform word spotting or "robust parsing" rather than full parsing of the users’ input. The point is that co-reference resolution is hard - and not just for machines. Among other themes, the 6th Message Understanding Conference (MUC-6) in 1995 dealt with co-reference evaluation. It was found that human inter-annotator agreement on co-referring nouns and noun phrases (which is only a sub-set of co-referring expressions) was so low that the systems being evaluated could not improve much before they went up against the uncertainty about the applied metric itself [Hirschmann et al. 1997]. However, with the increased sophistication required of the language processing component in interactive speech systems for complex, large-vocabulary tasks, co-reference resolution is becoming a practically important research topic.
Discourse segments are supra-sentential structures in spoken or written discourse. They are the linguistic counterparts of task structure and in the conversational theory of Grosz and Sidner [1986], intentions are restricted to those that are directly related to discourse segments. Each discourse segment is assigned one intention only, the discourse segment purpose. Furthermore, the intention as determined by the originator of a given discourse segment must be recognisable by the interlocutors in order to serve as a discourse segment purpose. Consider the example in Figure 3. In utterances S9a through S10a the purpose of the (date) discourse segment is to fix a date for the start of the journey. With the confirmation in S10a the system closes the segment and opens a new discourse segment, i.e. the hour segment, with the request in (S10b). However, the user’s utterance in U10a does not continue the hour segment. The system correctly interprets this utterance as a request for re-opening the date segment, and starts by stating its current information followed by re-negotiation of the departure date.
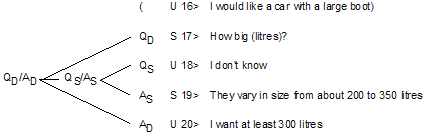
The example illustrates that the parts of a discourse segment have particular roles, just like words in a phrase [Grosz and Sidner 1986]. The request-inform-confirm structure, for instance, is very common in discourse segments. Other commonly described segment structures are presentation/acceptance [Clark and Schaeffer 1989] and initiative/response [Ahrenberg et al. 1995, Carletta et al. 1996a]. LINLIN, a natural language dialogue system, employs dialogue grammars for such structures to control the dialogue [Jönsson 1993]. The dialogue grammars are extracted automatically from empirically annotated dialogues (Figure 6). Note how the grammar symbols combine dialogue acts and topics.
More elaborate relations between discourse segments than just the structural sequence of speech acts have been elaborated in Rhetorical Structure Theory (RST). RST was originally developed for written text segmentation [Mann and Thompson 1987a] and later applied to dialogue systems [Fischer et al. 1994, Stein and Maier 1994]. RST describes relations between discourse segments hierarchically. An example is shown in Figure 7. Asymmetrical relations obtain between the nucleus which contains highly relevant information and satellites which contain less significant information. A relation is described in terms of four fields as exemplified by the following description of the evaluation relation in Figure 7:
- Constraints on the nucleus: the participants may possibly expect a given claim in the nucleus to be true.
- Constraints on the satellite: the participants either already believe the satellite or will find it credible.
- Constraints on the combination of nucleus and satellite: agreeing on the satellite will increase the participants’ shared belief in the nucleus.
- The effect:The shared belief in the nucleus between the participants is increased.
Other relations are solutionhood, cause, and reject. The extra information provided by the more elaborate segment relations may be used in the generation of more appropriate system utterances.

The above is adapted for web from [Bernsen et al. 1998b].