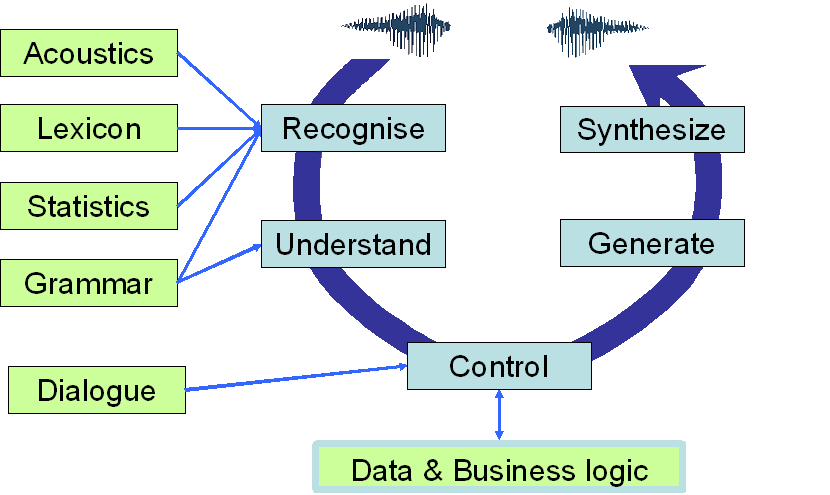
Speech Interaction Theory
The speech layer concerns the relationship between the acoustic speech signal and a, possibly enriched, text (lexical string). The relationship is not simple. Speech includes a number of prosodic phenomena—such as stress, glottal stops, and intonation—that are only reflected in text in a simplistic manner. Conversely, words and their different spellings as we know them from text, do not have natural expressions in speech. The text is adapted for web from [Bernsen et al. 1998b].
Speech recognition must cater for extra-linguistic noise and other phenomena, such as that the speech rate varies over time, the speech signal is mixed with environmental noise from other people speaking, traffic and slamming doors, the pronunciation varies with the speaker, and speech from different participants may overlap, for instance with the system’s utterances [Waibel 1996, Baggia et al. 1994].
Speech input
The input to the interactive speech system is an acoustic signal which typically, but not always, represents a spoken utterance. The transformation of the acoustic signal into some lexical representation, such as a word sequence or lattice, is called speech recognition.. Basically, speech recognition is a mapping process in which the incoming acoustic signal is mapped onto the system’s repertoire of acoustic models, yielding one or several best matches which are passed on to linguistic processing. The dominant speech recognition technology uses hidden Markov models combined with a dynamic programming technique [Bahl et al. 1983, Rabiner 1988, Kamp 1992]. The acoustic models may represent, for instance, triphones (context-dependent phonemes), phonemes, word forms or entire phrases. For historical reasons, acoustic models are sometimes called word models, but note that the number of acoustic models used may be very different from the vocabulary size which is the number of lexical entries that may occur in the output from the recogniser.
Current speech recognition techniques are typically limited to the extraction of lexical references, excluding information on pauses, stress etc. The machine therefore has much more difficulty interpreting what the user said than humans have, because humans are also able to use prosody to decode input from their interlocutors [Buchberger 1995]. However, the Verbmobil system uses stress and pauses to support, e.g., semantic disambiguation.
Typical measures of recognition quality are word accuracy and sentence accuracy. Word accuracy (or precision) is the proportion of correctly recognised words to the total number of words in an orthographic transcription of the input. Similarly, a sentence has been correctly recognised if every word it contains has been recognised correctly and no extra words have been inserted.
The recognition may assume isolated words (words spoken one at a time, clearly separated by pauses), connected words (words pronounced as isolated words, but with less stress and no, or little, separation) or continuous speech (standard naturally spoken language with contracted words and no separation of words) as input. Isolated and connected word recognition techniques are somewhat simpler than continuous speech recognition and yield better recognition results. However, those techniques require that the user speaks with a strained, unnatural voice, which is unnatural and in the longer term may damage the vocal apparatus.
When accepting connected words and continuous speech, the recogniser has some simple syntactic model (or grammar) of utterances. Typical examples are bigrams (allowed word pairs) and finite transition network grammars. The amount of syntactic constraints to impose is a trade-off: syntactic constraints increase the likelihood that input conforming to the model is recognised correctly, but highly constraining syntactic models allow fewer user utterances to be recognised.
In general, it is desirable to have available a large number of acoustic models for spontaneous speech recognition. In practice, the number needed depends on the task and the user group. On the other hand, a large number of acoustic models both increases the search space with the results that more memory is required and a faster CPU is needed to maintain real-time performance, and the models tend to become more similar to one another, making it harder for the recogniser to find the right match. This trade-off is similar to that between the syntactic models mentioned above.
A frequently adopted approach to avoid these trade-off problems is to let the active grammars and the active vocabulary (and the acoustic models needed) be contextually constrained by the focus set. If the sub-languages related to different focus sets are sufficiently different in nature, and each is smaller than the language of the application, then contextual constraints may be employed whilst keeping low the risk of users not being able to conform to the constraints. Often, however, equally good results may be obtained by using a phrase spotting technique where the recognition concentrates on extracting keywords or key phrases from the input.
Recognition may run in real time or batch. For interactive systems, real time recognition is a necessity. Today’s commercial recognisers run in real time, perhaps with a slight delay for long utterances.
Recognition may be speaker dependent or speaker independent. Speaker independent recognition is necessary in all public service systems. Speaker dependent recognition has better performance and may be used in, e.g., personal computers.
Recognition may be speaker adaptive, i.e. the speech recognition may adapt to groups of users (sex, dialect, language) or may be individually trained. The latter is often the case with speaker dependent systems. However, speaker independent recognition may extend its vocabulary through online training (automatic or explicit), or it may recognise which language the user speaks among several different ones.
Two examples of current state-of-the-art recognisers are the IBM voice dictation system and the Philips continuous speech recogniser. IBM provides as part of the operating system Warp4, a recogniser which is intended for dictation and command purposes: it is real time, speaker independent with 30K words vocabulary and 90% word accuracy, speaker adaptive with 95% word accuracy and adding up to another 40K words, and accepts isolated word dictation and continuous speech commands [IBM 1996]. Philips has produced German and Swiss public train timetable information systems which use speech recognition via the telephone: the recogniser is real time, speaker independent, recognises continuous speech, has a word accuracy of about 75%, and a fixed vocabulary of about 1800 words [Aust et al. 1995]. The accuracy of the two systems cannot be compared. The IBM measures concern the overall performance using a good microphone, whereas the Philips measure concerns only the recogniser and is measured over an ordinary telephone line.
Speech output
Computer speech is produced by generating an acoustic speech signal from a digital representation.
Hansen et al. [1993] distinguish coded and parametric speech. Coded speech is pre-recorded words and phrases which are concatenated and replayed. Coded speech ensures a natural voice and is widely used in voice response systems. Drawbacks are that prosody is impossible to get completely right, and that maintenance of system phrases may be difficult and costly. New phrases to be added must be produced by the speaker who did the previous recording(s), and using the same voice quality, or all words and phrases must be re-recorded.
For parametric speech (or synthetic speech), a synthesiser generates an acoustic signal based on a model of human speech. Prosodic features, such as intonation, pauses and stress, may be included in the model and employed on the basis of prosody markers from the system utterance generation inserted on the basis of discourse information [Hirschberg et al. 1995]. Parametric speech makes it easy to generate new system phrases at any time. A drawback is that the parametric speech quality is still low for many languages.